Introduction
“Indexing” refers to the process of synchronizing block data from AElf blockchain nodes to a locally centralized ElasticSearch environment for storage.
This system then provides various data interfaces. Whether you are a dApp developer looking to build exciting applications on the AElf blockchain or just curious about how the AElf node’s scanning system operates, this document is suitable for you.
Overall Workflow
The overall workflow of the indexer, starting from the AElf nodes, pushing block data to the DApp, getting the desired on-chain data.
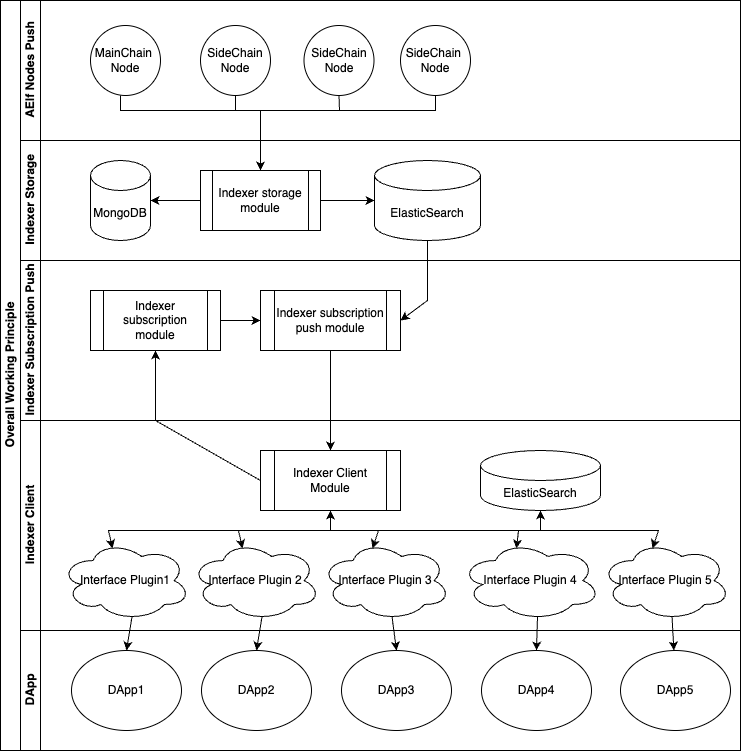
1. AElf Node Push
The AElf Indexer enhances functionality for AElf nodes, enabling automatic asynchronous or synchronous transmission of historical or latest block information to the RabbitMQ message queue. The AElf Indexer’s storage module then receives and processes the relevant block data.
2. Indexer Storage
Upon receiving block data from RabbitMQ, the Indexer storage module identifies and processes the data, identifying any forked blocks. During this process, some auxiliary data is stored in MongoDB, but ultimately, all block data (excluding forks) is stored in Elasticsearch. The data is organized into different indices based on the structures of Block, Transaction, and Logevent.
3. Indexer Subscription and Push
Subscription: Consumers of the AElf Indexer can initiate subscriptions for block-related information through the subscription API. Currently, subscriptions primarily support block height, block transactions, and block transaction event dimensions, especially subscribing based on transaction events, which is applicable in various scenarios. After making a subscription API request with a client ID, a subscription version is returned, which is noted and later written into the client interface plugin developed subsequently.
Push: Upon receiving a subscription request, the AElf Indexer subscription and push module fetches data from Elasticsearch based on the subscription requirements and streams the data to the Kafka message queue.
4. Indexer Client
The Indexer client receives subscribed block data from Kafka and passes it to the interface plugin for processing. Interface plugins are developed separately and handle various transactions and events within blocks, storing the processed result set in a specific Elasticsearch index. Based on requirements, GraphQL interfaces are defined, utilizing Elasticsearch as a data source to develop business logic and expose the data externally.
5. DApp Integration
Within the DApp, desired data can be requested by directly calling the GraphQL interface exposed by the AElf Indexer client interface plugin, based on the client ID.
Why Indexer Is Needed
The role of the Indexer in the AElf blockchain is crucial. It synchronizes block information from AElf nodes to a local ElasticSearch environment, providing developers with convenient and efficient data access interfaces. By enabling real-time or historical data asynchronous or synchronous transmission, the Indexer enhances the functionality of AElf nodes, allowing them to handle block information more flexibly. Moreover, it offers robust data querying and subscription mechanisms. This mechanism enables decentralized application (DApp) developers to easily subscribe to and retrieve relevant information about specific blocks, transactions, or events, facilitating the development of applications on the AElf blockchain. With the Indexer, developers can establish indexes, query, and analyze blockchain data more effortlessly, improving DApp development efficiency and providing convenience for broader blockchain data utilization.